




딥러닝(Deep Learning)을 이용한 비디오 기반의 화재감지 모델
(A Video-Based Fire Detection Using Deep Learning Models)
화재는 비일상적인 사건으로 인명과 재산에 심각한 영향을 미치며 다른 재난보다 확산 속도가 빠르기 때문에 신속하고 정확한 감지와 지속적인 감시가 요구된다. 최근 신속하고 정확한 화재 감지를 위해 영상(Video, CCTV 등)으로 획득한 이미지를 기계학습(Machine Learning)을 이용해 화재 발생 여부를 감지하는 화재 감지 시스템이 주목을 받고 있다. 이번 소방기술소식에서는 기계학습 기술 중 정확도가 가장 높은 딥러닝(Deep Learning, 여러 층을 가진 인공신경망을 사용하여 머신러닝 학습을 수행하는 심층학습)을 이용한 비디오기반의 화재 감지 시스템을 소개하고자 한다.

미국 소방국(National Fire Protection Association, NAPA)에 따르면 2017년 한해에 131만9,500건의 화재가 발생하였고 3,400명의 민간인 사망자가 발생했다. 이러한 민간 화재 사고 시 발생하는 인명피해와 약 230억 달러 규모의 재산 손실을 줄이기 위해 정확한 화재 탐지가 필요 했다. 일반적으로 기존의 화재 경보 및 화재 식별은 컴퓨터 비전에 의한 탐지와 전통방식인 연기 또는 열 센서감지 등 두 가지 기술을 기초로 한다. 또한 이러한 기술들은 센서를 확인하기 위해 사람의 개입이 필요하다.
이번 딥러닝 기반의 비디오 화재 감지 기술은 사람의 개입을 최소화시켜 혹시나 있을 휴먼에러를 방지하기 위한 기술이며, 이러한 에러율을 낮추기 위해 전 세계에 발생한 여러 가지 화재 상황들의 이미지 및 영상을 분석하여 정확한 정보를 전달하고자 한다.
연구 초기에는 화염의 정적 또는 동적 특성을 파악하는 것이 쉽지 않기 때문에 색상에 많은 투자를 하였다. 이후에는 날씨와 연동시켰으나 연기의 색과 움직임으로는 일시적인 화재 패턴을 분석하는데 한계가 발생하였기에 딥러닝 방식의 화재 탐지방식을 제안하게 되었다.
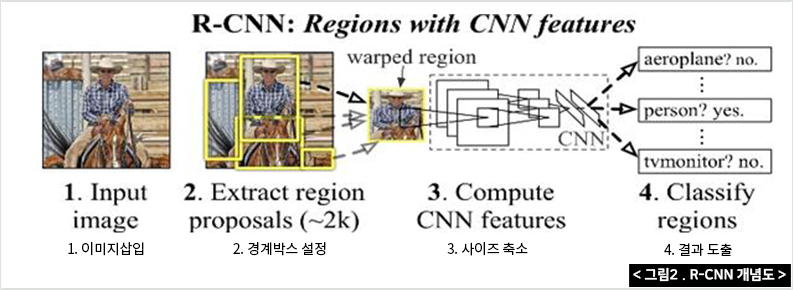
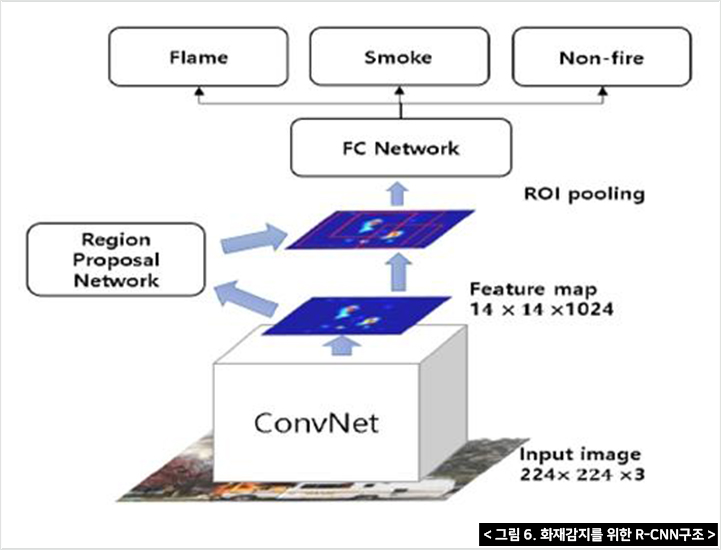
첫 번째 단계로는 심층객체를 사용하여 비디오 프레임에서 SRoFs 또는 비화재 객체를 감지하며, 탐지모델인 Faster R-CNN은 CNN 추출기와 분류기가 있는 경계박스로 구성되어 있다. 경계박스(인식 구역설정)는 세 가지 상황 즉 화염, 연기 그리고 불이 아닌 다른 상황의 위치를 찾는다. 또한 화재지역 전체가 하나의 경계박스로 취급된다.
R-CNN은 2012년 ILSVRC대회에서 AlexNet이 세상에 공개한 이미지 분류(Classification)분야이며, 이후 R-CNN을 수정·보완하여 성능, 속도 등을 향상 시킨 것이다. 기본적인 R-CNN의 구조는 아래의 그림처럼 1)이미지 삽입 → 2)2,000개의 경계박스를 설정하여 추출 → 3)CNN모델에 넣기 위해 동일한 사이즈(227X227 pixel size)로 축소 → 4)결과 도출의 순서로 진행된다.
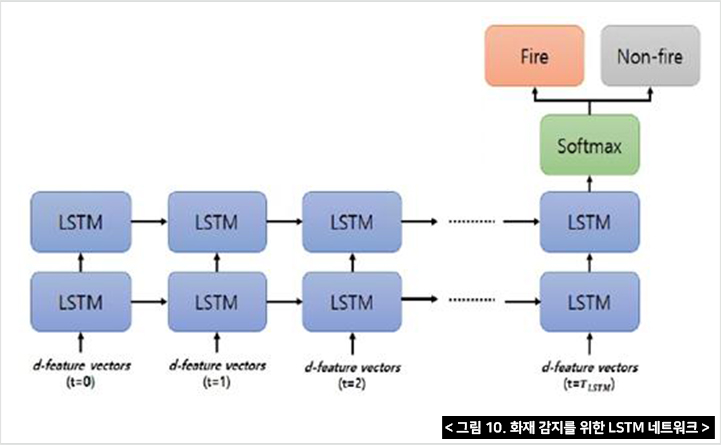
두 번째 단계는 화재의 역동적인 활동을 포착하기 위해 일시적으로 축적되며, 단기적인 화재결정은 2단계 LSTM네트워크에서 이루어진다. 이 LSTM이 연속적으로 화염과 연기의 특징을 분석하고 그 내용들 축척하여 화재와 비화재중 하나를 결정하게 된다.
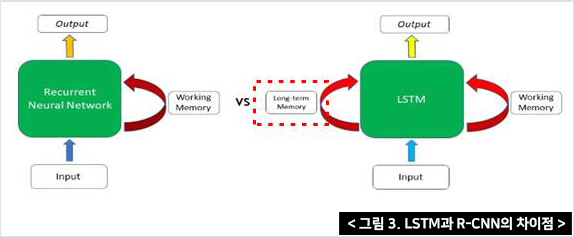
여기서 LSTM은 R-CNN의 한 종류이며 비슷하게 기능하지만 LSTM의 게이트 메커니즘(Gating Mechanism)은 R-CNN과 구별된다. 즉, R-CNN은 최종적인 단기기억으로 결과를 도출하지만 LSTM은 처리과정의 모든 상황을 종합적으로 판단하여 처리할 수 있다.
이러한 특성으로 인해 LSTM은 R-CNN의 단기기억(Short-term memory) 문제를 해결한다.
마지막 단계에서는 화재의 최종적인 결정을 위해 축적내용들을 토대로 화재의사결정을 진행하게 된다.
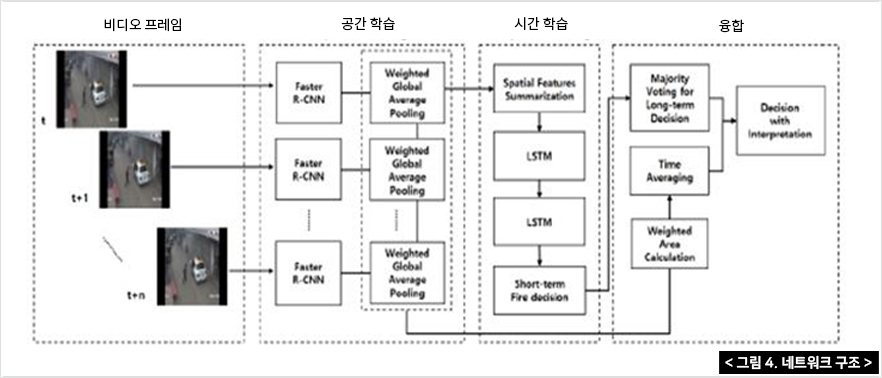
그림 5는 각 블록의 결정 기간을 보여주는 타이밍 다이어그램을 나타내고 있다. 각 비디오 프레임마다 화재가 감지되며 감지된 경계박스의 R-CNN특징은 LSTM에 축적된다.
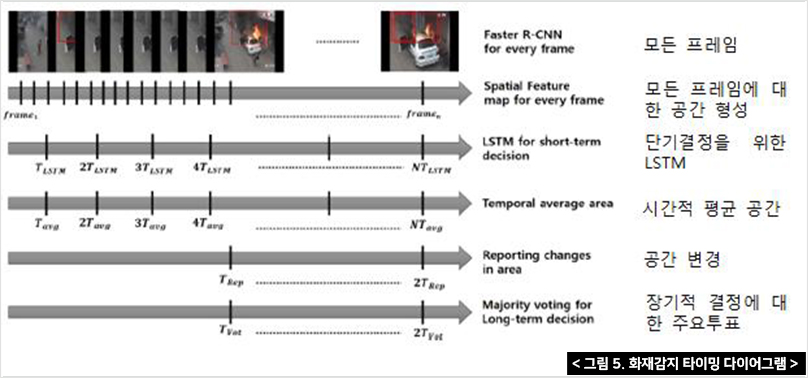
Faster R-CNN은 R-CNN과 지역제안 네트워크(RPN)를 모두 결합해 완전히 연결된 계층을 배제한 뒤 콘볼루션 네트워크를 공유하는 CNN기반 객체 탐지 방식이다.
Faster R-CNN이 화염, 연기, 비화재 물체의 종류를 감지할 때, 화재와 유사한 단일 프레임에서 비화재 물체(일몰, 굴뚝연기, 구름 등)로 인해 잘못된 탐지가 발생할 수 있다.
비화재에 관한 정보는 하나의 경계박스로 정보를 인식하며, SRof(Suspected Regions of Fire, 화재의심지역)탐지가 컨텍스트를 더 잘 반영하기 때문에 더욱 확실한 분류가 가능하다.

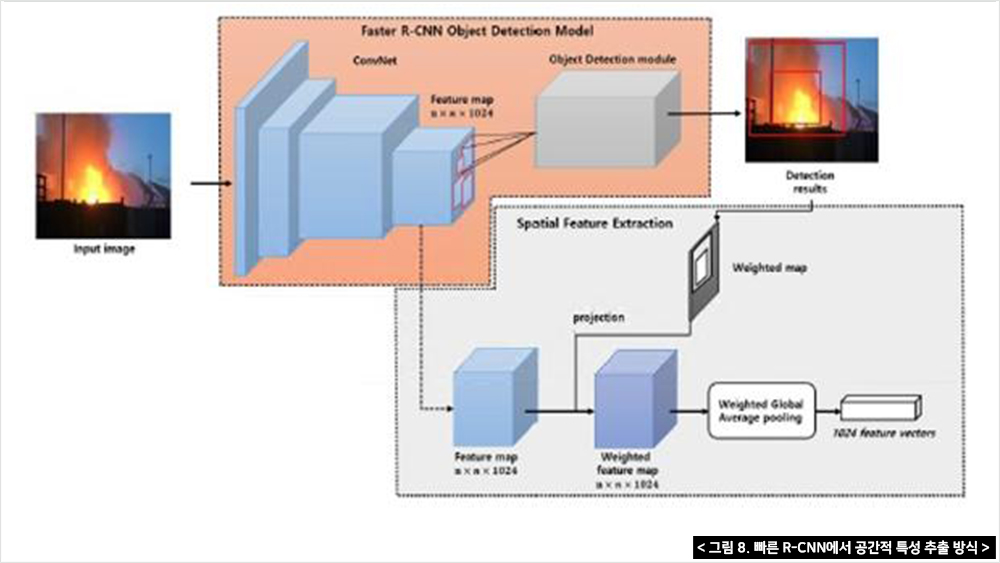
경계박스의 좌표는 n*n*d 활성화 맵에 투영하여 공간형상을 추출한다. 이러한 공간설정을 통해 화염과 연기 그리고 불 이외의 물체를 포함하여 다양한 공간적 특성을 인식할 수 있다. 아래 그림 8은 화재 및 비화재 물체의 유형 기능 추출의 일부를 보여주고 있다.
아래의 그림 9는 여러 SRoF가 있는 경우를 보여주고 있다. 이처럼 여러 개의 경계 상자가 포함될 수 있기 때문에 Faster R-CNN은 둘이상의 SRoF 또는 비화재 개체를 제공할 수 있다. 따라서 화재나 비화재 물체의 시간적 행동을 더욱 깊이 고려하기 위해 여러 영역을 세심하게 파악해야 한다.

시간적인 상황을 고려하지 않고 화재를 판단하는 것은 적절하지 않다. 그래서 이 연구에서 제안한 방법은 단기 LSTM을 이용한 공간특성의 변화를 취합하여 화재, 비화재 여부를 판단했으며, 화염과 연기를 분리하지 않고 LSTM의 경계박스 내의 공간적 특성만을 축적하여 화재여부를 판단했다.
R-CNN의 속도를 빠르게 하기 위해서 여러 장의 스틸이미지가 필요 했고 이를 위해 많은 데이터 소스를 축적하였다. 최종적으로 2만2,729개의 화염, 2만3,914개의 연기, 2만7,244개의 비화재 이미지로 구성된 7만3,887개의 스틸 이미지를 데이터 집합으로 구성했다. 이미지의 용도는 교육 75%, 검증 15%, 테스트 데이터 10%로 나뉜다.
고속 R-CNN의 성능은 mAP(mean Average Precision, 평균 정밀도)에 의해 측정되며 표 2와 같다. 화염 및 연기 감지 샘플 결과는 그림 9와 같다. 구름, 굴뚝 연기, 조명등, 증기 등에 대한 몇 가지 잘못된 양성 탐지가 있는데 시간적 특성을 고려하지 않고서는 거의 탐지할 수 없는 것이다.

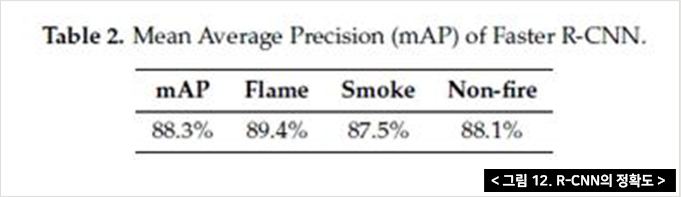
그림 12의 결과와 같이 시간적인 요소를 배제하고 순수한 스틸이미지만으로 판독하였을 때 80% 후반의 정확도가 나오는 것을 알 수 있다. 그래서 본 연구에서는 더욱더 정확한 판독을 위해 시간이 포함된 영상으로 판독해보았다.
유튜브에서 672개의 화재 동영상과 637개의 비화재 동영상으로 구성된 1,309개의 동영상을 수집했다. R-CNN에서와 같이 불이 아닌 물체의 비디오 클립은 구름, 굴뚝 연기, 조명등과 같은 부정적인 예들을 포함되어있다. 그림 13은 LSTM 교육용 비디오 데이터 집합의 화염, 연기 및 비화재 물체의 샘플을 보여준다.

화염과 연기를 구별하지 않았으며 비디오 클립은 초당 30프레임을 가정할 경우 약 2초간 지속되는 15프레임의 중첩이 있는 60개의 연속 프레임으로 나뉜다. 이는 LSTM 네트워크가 단기간 동적 동작을 포착한다는 것을 의미한다. 화재 또는 비화재로 1.5초마다 화재 여부를 결정한다.
LSTM 교육을 위해 유튜브 동영상 60개 프레임 동영상 8,527개, 7,547개의 네거티브 사례를 준비했다. 사례에서 75%의 데이터가 교육용으로 선택되었다. 각 동영상에서 경계박스와 각각의 연속된 프레임마다 그에 상응하는 1,024차원 형상을 입수하였고, 이것을 LSTM에 일련의 순차적으로 입력하였다.
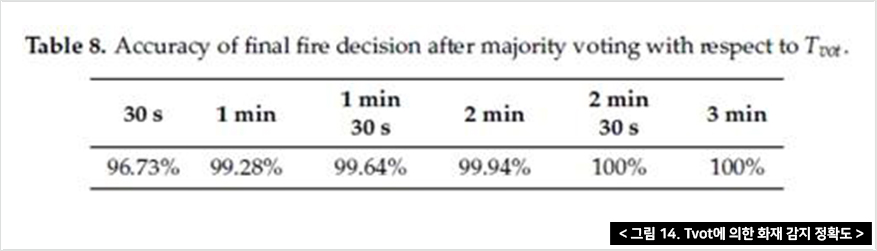
Tvot(시간이 포함된 결정) 중 LSTM 단기 화재 결정은 최종 화재 결정을 위한 다수결에 관여한다. 이렇게 단기영상으로 판독하여도 정확도 최대 97.92%까지 높아진다.
또한, 연기(또는 증기)와 화염 부분의 변화를 관찰했다. 실험에서 우리는 Tvot을 1분을 설정했다. Faster R-CNN은 종종 진짜 연기와 증기를 혼동하기 때문에 그 결과는 두 영역을 구별하지 않고 포함한다. 그림 15의 영상에서는 화염으로 불이 시작되지만 한 남성이 물을 부어 불을 끈다. 그리고 시간이 지남에 따라 증기가 증가하기 시작한다. 그림 15는 비디오 시퀀스의 샘플 프레임을 보여주고, 그림 16은 화염과 연기 영역의 변화(프레임 안의 픽셀)와 시간의 경과에 따른 최종 결정을 나타낸다.

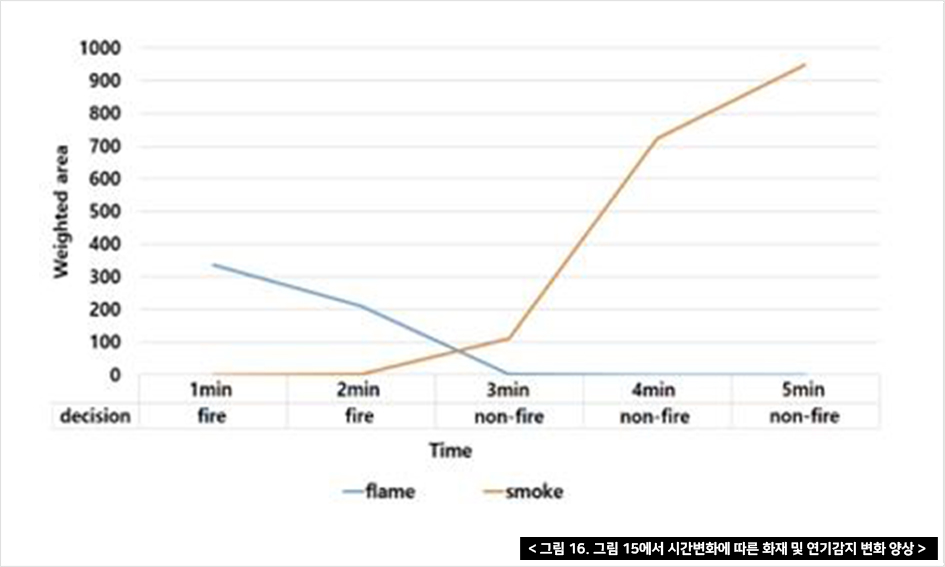
그림 17은 일출 동영상을 나타내고 있으며 Faster R-CNN이 화염 물체를 잘못 감지하고 화염 면적이 증가하더라도 최종 결정은 그림 17과 같이 비화재로 인식됨을 알 수 있다. Faster R-CNN이 구름, 맨홀의 증기, 일몰 등 비디오 클립에 대해 잘못된 물체 감지 기능을 제공함에도 불구하고 다른 36개 비디오 클립에 대해서도 유사한 실험 결과를 얻었다. 그림 17의 영상에서는 약 3분 동안 화재로 인식하다가 이후에는 비화재로 인식하고 있으며, 아래에 그래프에서는 성공적으로 해석된 화재의 변화를 보여준다.
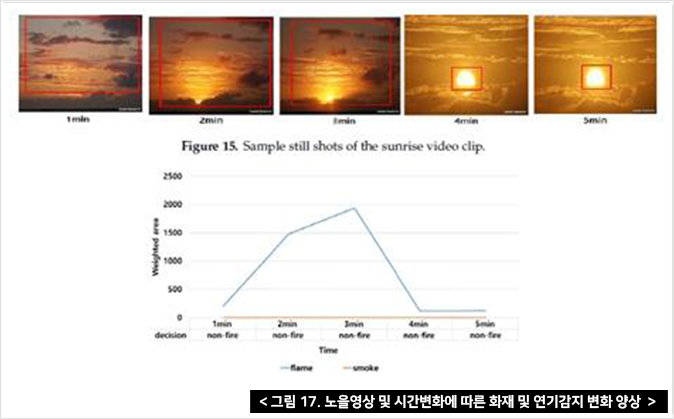
그림 18은 지속적으로 감소하는 화재의 스틸 사진을 보여주고 있으며, 아래의 그래프는 화재의 변화를 포착하고 있다.
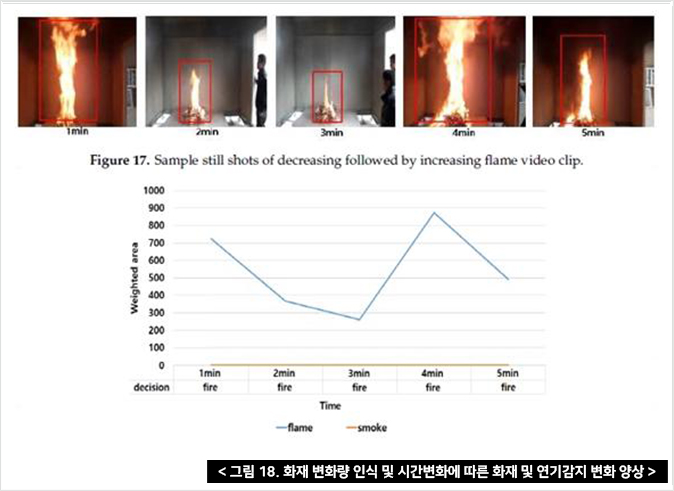
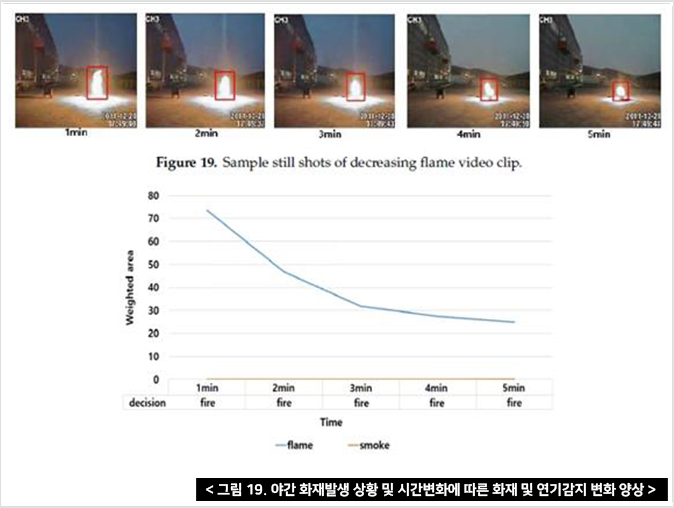
이 연구에서는 인간의 탐지 과정을 모방하는 DTA라고 불리는 딥러닝 기반의 화재 탐지 방법을 제안하였고 DTA 프로세스가 잘못된 화재 감지를 크게 줄일 수 있다고 가정했다. 제안된 방법은 faster R-CNN 화재 감지 모델을 사용하여 SRoF의 공간적 특징을 바탕으로 탐지한다. 이후 연속 프레임의 SRoFs와 비화재 영역에서 요약한 특징을 LSTM이 축적하여 단기간에 화재 발생 여부를 분류한다. 그 후 연속적인 단기 결정은 장기간의 최종 결정을 위한 다수결로 결합된다. 또한 화염과 화재의 영역을 모두 계산하고 그 시간적 변화를 보고하여 화재의 동적 거동을 최종 화재 결정으로 해석한다.
제안된 방법은 오탐지를 줄이고 시간적 변화를 성공적으로 해석함으로써 뛰어난 화재탐지 정확도를 제공하는 것이 실험으로 입증되었다.
이러한 연구 성과가 향후 민간에 도입되었을 때 화염과 연기로 인해 소방관들의 잘못된 출동이 감소할 수 있다. 또한 이 실험은 미래의 화재 연구를 위한 자산이 될 수 있을 것이라고 생각한다.
저 자 : Byoungjun Kim and Joonwhoan Lee(Division of Computer Science and Engineering, Chonbuk National University, Jeonju 54896, Korea)
원문출처 : 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution(CC BY) license
(http://creativecommons.org/licenses/by/4.0/).
글. 김현수|한국소방안전원 정책연구소 연구원
