1.1 국내 화재발생 및 피해 현황 국내 화재 발생 현황은 매년 4만 건 내외로 2017년 소방청의 “1차 화재피해 저감 정책”을 통해 화재 발생건수의 감소세를 보였으나, 화재로 인한 인명 및 재산 피해는 2011년 이후 현재까지 꾸준히 증가하는 추세를 보이고 있다. 또한 최근 10년간의 평균 화재 건수는 연 42,331건이며 그 평균 피해는 인명피해가 연 2,215명(사망 308명, 부상 1,907명), 재산피해는 연 4,765억여 원으로 화재발생 건수에 비하여 물적‧인적 피해는 날로 확대되고 있다.

1.2 화재취약지구 예방대책 수립 현황
화재 피해를 미연에 방지하고자 국내에서는 화재 발생의 우려가 높거나 화재 발생 시 그로 인한 피해가 클 것으로 예상되는 화재취약지구를 소방법에서는 화재경계지구로, 건축법에서는 방화지구로 지정하여 화재안전관리를 시행하고 있다. 그러나 본 연구 결과, 이러한 화재취약지구의 실질적 화재 안정성 확보를 위해서는 소방시설의 적용 및 관계자에 대한 안전교육만으로는 분명한 한계가 있음이 나타났다.
일반 건축물에 비해 화재취약지구의 화재 발생 시 그 피해 규모가 커지는 주요 원인으로는 소방차 진입통로의 협소, 소방활동 공간의 부족, 목조나 샌드위치 패널 등 비내화구조로 구성된 건축물 등으로 분석되었다. 따라서 본 연구에서는 화재경계지구나 방화지역과 같은 화재취약지구의 설정이 아닌 건축물 속성정보와 위치정보를 토대로 인공지능을 학습하여 건축물단위 화재 위험도를 등급화함으로써 제한된 자원 내에서의 최고 효율을 가진 데이터 기반의 효율성 높은 예방 대책의 수립을 제안하고자 한다. 여 원으로 화재발생 건수에 비하여 물적‧인적 피해는 날로 확대되고 있다.
2.1 기존 연구 과거 화재 이력에 대한 행정구역별 통계 데이터만으로 예방 대책을 세우는 것은 한계가 있어, 이를 보완하는 방법으로 실제 화재가 발생하는 건물 단위의 위험도 예측 및 관계 기관에서 활용할 수 있는 시스템 등을 활용할 수 있다. 즉, 활용 가능한 예측 정확도가 확보되고 건물 단위 화재 위험도 모델 개발이 우선 되어야 한다. 기존 연구 사례를 분석해 본 결과, 주로 전문가 집단의 AHP 분석을 활용하여 화재위험지수를 작성하였고, 데이터 기반의 분석을 통해 시도-시군구별 화재 위험지수를 산정해 오고 있음을 알 수 있었다. 그러나 이러한 분석 결과를 실제 정책이나 화재안전점검 우선순위 선정 등 예방활동에 활용하기에는 다소 제약이 존재한다. 이와 관련한 국외 사례를 살펴보면, 미국 아틀란타 소방청(Atlanta Fire Rescue Department, AFRD)에서 구축한 Firebird와 미국 뉴욕 소방청(NYD Fire Department, FDNY)에서 개발한 Firecast 모델을 대표적 케이스로 들 수 있다. 이러한 사례의 공통 특징은 관할 구역의 모든 건축물에 대하여 화재 발생 위험도를 예측하고 제한된 시간과 예산으로 효율적인 건물의 점검 우선순위를 결정하는 것을 목적으로 두고 있는 것이다. 그러나 AFRD에서 구축한 FireBird의 경우 랜덤포레스트(Random Forest) 모델을 기반으로 개발된 예측모델로 약 71%의 높은 정확도를 보이지만 5,000개의 다소 적은 건축물 수를 대상으로 하였으며, 건축물의 속성정보 중 면적, 층수, 필지 등의 제한적 변수를 활용하였기에 그 한계가 존재했다. 반면 FDNY에서 개발한 Firecast의 경우 과거 화재 기록과 함께 건축물의 속성정보와 세금 납부 내역 등의 다양한 변수를 활용해 약 77%의 정확도를 보이고 있으나, 화재 발생 위험도가 아닌 화재 안전 점수를 계산하여 우선 점검 여부를 판단하고 공공 및 민간의 직접적인 점검을 통해 위반 현황을 적발하고 현장 출동에 익숙해짐으로써 그 피해를 최소화하는데 목적을 두고 있다는 점에서 딥러닝과 같이 가능한 모든 변수를 활용하고 건축물의 화재사고 발생 여부를 예측하고자 하는 본 연구의 목적과는 차이가 있었다.
2.2 전국 건축물단위 화재위험 예측 알고리즘 개발
본 연구의 공간적 범위는 전국 허가를 득한 건축물 전체를 대상으로 하였으며, 이는 전국 건물화재 데이터 및 국토부 건축물 대장 정보 등의 건물속성을 중심으로 소방안전 빅데이터 플랫폼에서 제공하는 활용 가능한 데이터를 융합한 데이터이다.
시간적 범위는 2018년도 화재건수 4만여 건을 대상으로 목표 값으로 구성하였고, 건축물 정보와 에너지 정보 등 모든 데이터 기준을 2018년으로 하였다. 이는 실제 화재 데이터를 기반으로 학습 데이터의 시간적 오차를 발생하지 않기 위함이다.
내용적 범위는 소방청의 화재 데이터 및 국토부의 공공데이터의 건축물 관련 데이터 및 행정안전부의 도로명주소 데이터 등을 활용하여 데이터의 융합 방법론을 연구하였고, 실제 화재 데이터와 결합한 학습데이터를 구축하였고 딥러닝 기법을 활용하여 예측모델을 개발하였다. 또한 예측모델을 활용한 화재사고 위험도를 도출하여 유관기관 등에게 정보제공을 위한 서비스 개발을 수행하였다.
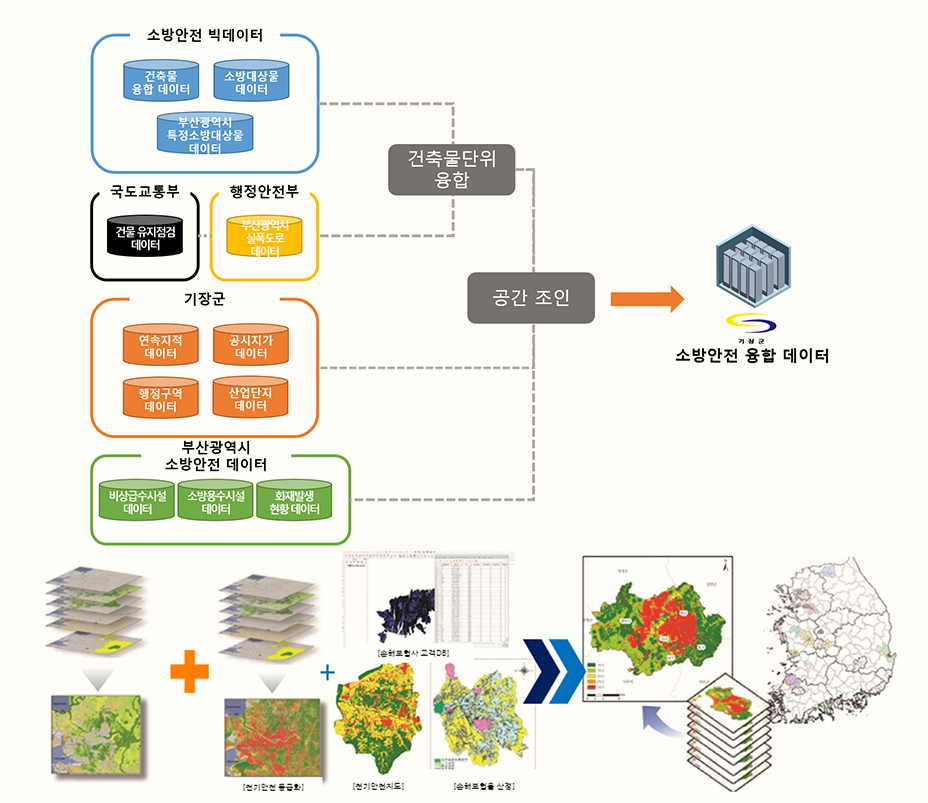
3.1 데이터 수집/정제/융합
건물단위로 데이터를 융합하여 화재 예측위험도를 도출하는 것이 목적이기 때문에 국가공간정보포털에서 제공하는 건물속성정보와 건물공간정보(shp), 행정안전부 도로명 건물데이터를 기준으로 소방안전 빅데이터 플랫폼에서 제공하는 소방안전 관련 데이터와 지자체별 건축물 정보 등 다양한 독립변수를 수집하였다.
이후 수집된 데이터에서 불필요한 속성을 제거하는 등 전처리를 수행하였고, 건축물 고유번호를 중심으로 건물단위로 데이터를 융합하여 최종 융합셋을 구축하였다. 이때 사용되어진 건물고유번호(BD_MGT_SN)는 행정안전부에서 사용하는 건물단위 고유번호로, 도로명코드 12자리, 읍면동일련번호 2자리, 지하여부 1자리, 건물본번 5자리, 건물부번 5자리로 총 25로 구성되어 있다.
데이터 융합과정을 거쳐 72개 속성, 약 600만여 개의 인스턴스를 가진 융합셋을 도출하였고 종속변수인 일반화재사고 데이터(9개 속성, 38000여개의 인스턴스)를 융합하여 화재유무 속성을 추가하였다.
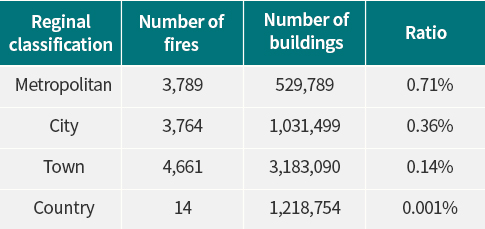
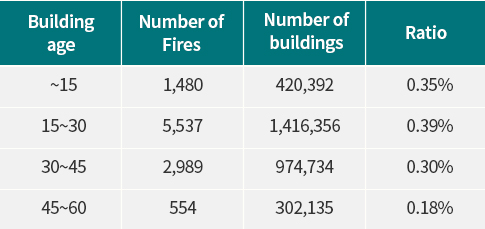
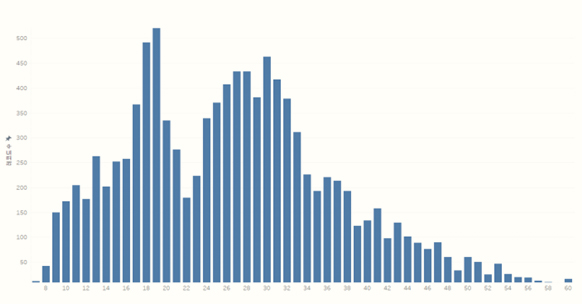
3.2 융합데이터 분석 지역적 구분으로 건물 수 기준으로 화재사고의 수를 비교하면 일반시, 특별시, 광역시, 일반군 순이나, 이를 해당 구분의 건물수로 나누어 계산하면 특별시, 광역시, 일반시, 일반군 순으로 화재가 많이 발생하는 사실을 알 수 있었다. 화재발생의 특징이 지역적인 차이가 있다는 가설에 의해서 특별시, 광역시, 일반시, 일반군으로 구분하는 속성을 만들었다. [표 2]와 같이 건물데이터의 수는 일반시, 일반군, 광역시, 특별시 순이지만 에너지 사용량 평균값은 역순으로 특별시, 광역시, 일반시, 일반군으로 많았다. 에너지 사용량이 높으면 화재위험이 높아짐을 알 수 있었다. 단독주택이 60%, 공동주택 8%, 제2종 근린생활시설 8%, 제1종 근린생활시설 7%로의 순서로 단독주택이 가장 많았고 일반시, 일반군의 경우 공동주택의 비율이 줄어듦이 나타났다. 업무시설의 화재 발생율은 1.6%로 가장 높았고, 공동주택 0.7%, 공장 0.4% 순으로 나타났다. 용적률은 대지면적에 대한 연면적의 비율로, 활용된 데이터셋에서 화재가 발생한 건물의 평균 용적률이 높은 특성을 나타내었다. 따라서 건물들의 용적률이 높을수록 건물밀도가 높아져 화재에 취약할 수 있다는 가정 하에 이를 설명변수로 활용하였다. 건물 건축일자로부터 건물연령을 도출하여 그 분포를 [그림 2]와 같이 확인하였다. 15년 이상 40년 이하의 건물이 데이터의 86%를 차지하고 있었다. 건물 연령대별 화재비율을 계산해보면, [표 3]과 같이 15년 이상 30년 이하 건물이 가장 높은 비율로 화재 사고가 발생했고 15년 이하 건물과 30년 이상 45년 이하 건물과 비교해보면 큰 차이는 보이지 않았다.
3.3 건축물 단위 화재위험도 예측모델 개발
모델개발을 위한 방법론으로 샘플링기법을 선택하였고, 학습 데이터셋 구축을 위해 데이터 변환, 모델링, 하이퍼파라미터 최적화 순으로 수행하였다.
언더샘플링 비율에 따라 모델성능 비교를 위해 샘플링 후 모델평가를 수행하고AUC(Area Under ROC Curve)와 ROC(Receiver Operator Characteristic)를 비교하여 높은 AUC를 지닌 모델을 선정하였다. 또한 화재 데이터의 수는 건축물의 수에 비하여 너무 적기 때문에 오버피팅의 위험성이 높은 오버샘플링보다는 전체 융합셋(5,965,126)에서 화재사고 중심으로 1:4의 비율로 언더샘플링 하여 학습데이터를 구축하고 ROC와 AUC를 활용한 결과 2:8의 비율로 언더샘플링한 모델의 AUC가 0.858로 가장 좋게 나타났다.
이후 17개의 설명변수와 화재발생유무를 종속변수로 설정하여 총 12개 계층의 순차모델을 생성하고 과적합 방지를 위해 Dropout 레이어를 추가하였다. 이를 활용하여 4,971개의 파라미터를 학습시켜 생성하고 테스트셋을 활용한 모델 테스트 최종 예측 정확도는 86.91%로 도출되었다.
3.4 검증 개발된 모델의 검증은 10-겹 교차 검증기법을 활용하여 만들어진 모델의 검증을 수행하였다. 10-겹 교차 검증 학습 단계별 검증 결과 87.1%로 안정적인 결과가 도출되었다. 또한 클러스터링 간 비교하여 적절한 클러스터 개수를 구하기 위해 Elbow method를 활용하여 클러스터 개수를 선정하였다. 예측 결과에 Elbow method를 적용한 결과 다음과 같은 결과를 보였으며, 이를 토대로 최적의 클러스터 개수를 5로 적용해 화재위험등급을 총 5단계로 구분하여 위험등급에 따른 집단의 수를 도출하였다
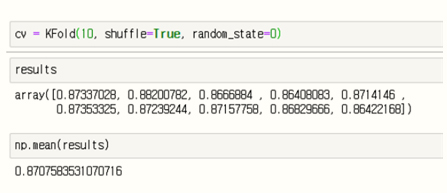
본 연구에서는 다양한 요인들의 복합적 작용으로 발생하는 화재사고에 대응하기 위해 인공지능 기법을 적용하여 보다 객관화하고 계량화할 수 있는 예측 기법에 대해 연구하였다. 구축된 융합셋을 활용하여 건물단위 화재위험 예측모델의 인공지능 기술을 활용하였고, 그 중에서 MLP의 깊은 신경망 모델을 통해서 학습하였다. 이후 하이퍼 파라미터 최적화 과정을 거쳐 건물화재 예측 학습모델을 개발하고, 10-겹 교차검증의 모델 검증과정을 거쳐 도출한 결과 87.1%의 정확도를 확보하였다. 예측결과를 사용자가 인지하기 쉽도록 위험, 경계, 주의, 관심, 안전 5가지 등급으로 화재위험도를 등급화하기 위하여 K-평균 클러스터링을 수행하였다. 또한 GIS 기술을 활용한 건물화재 위험도지도 제공을 위해 분석 및 예측한 결과를 화재위험도 5등급화으로 분석하여 지도기반 시각화를 수행하였고 이를 서비스화 하였다. 본 연구에서 구축한 건물단위 융합데이터셋은 다양한 스마트시티 활용 모델 개발에 있어 기반 데이터로 활용될 수 있을 것으로 판단되며, 또한 공간정보와 인공지능 기술을 융합하여 보다 과학적으로 화재 예측을 할 수 있는 알고리즘을 제시한데 의의가 있다고 할 수 있다. 아울러 본 연구를 토대로 유관 기관들이 실시간으로 화재 위험 정보를 확인할 수 있도록 시스템을 구축하여 제공한다면 매우 효율적인 공공 서비스가 될 수 있을 것으로 기대된다.
글. 심동섭(주식회사 업데이터 연구원)